
Ainized-Detectron2 (ENG)

한국어로 보시려면 여기를 클릭해주세요.
Detectron2 is the object detection open source project [Link] based on the pytorch made in the Facebook AI Research (FAIR). Modular design makes Detectron2 more flexible and extensible. Detectron2 provides implementations of object detection algorithms such as panoptic segmentation, DensePose, Cascade RCNN, etc with a variety of backbones.
you can run it right through this Link. Or,
In this Ainize project [Link], after selecting one of the inference models, you can get a result image. All the inference models used Resnet 50 + FPN (Feature Pyramid Network) as a backbone.
Instance Segmentation
The Instance segmentation used Mask R-CNN. Semantic segmentation treats multiple objects of the same class as a single entity. On the other hand, instance segmentation treats multiple objects of the same class as distinct individual objects (or instances).
Person Keypoint Detection
Person keypoint detection measures and estimates the position of the human joints as keypoint. In the Mask R-CNN paper, the location of the keypoint is modeled as a one-hot mask, and Mask R-CNN adopted to predict K masks, one for each of K keypoint types.
Panoptic Segmentation
Panoptic segmentation addresses both stuff and thing classes, unifying the typically distinct semantic and instance segmentation tasks. thing classes are countable objects such as people, animals, tools. Stuff classes are amorphous regions of similar texture or material such as grass, sky, road. If you see the below picture, you can understand what is panoptic segmentation.
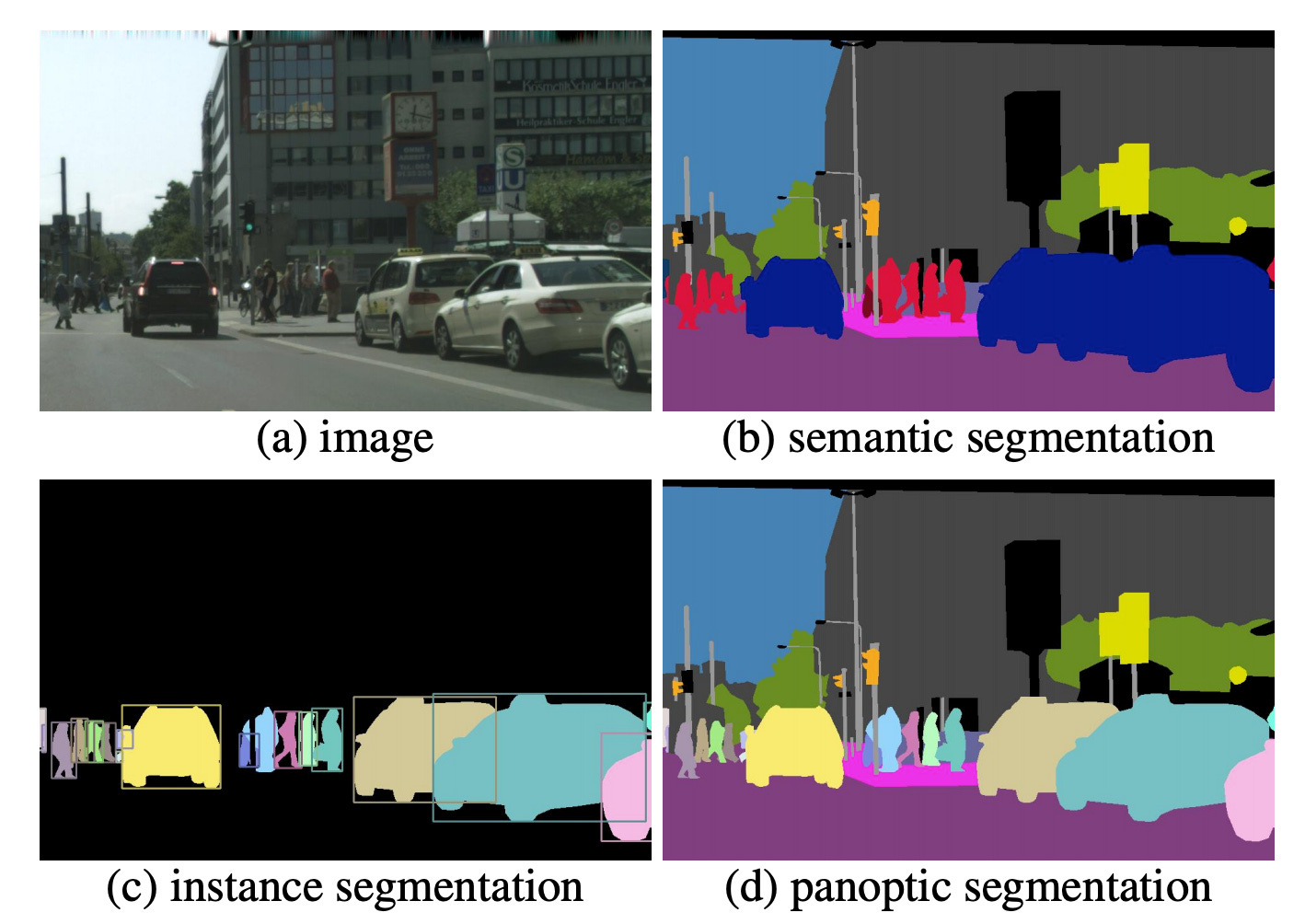
The inference model used here was introduced from Panoptic FPN. In the previous model of panoptic FPN, instance and semantic segmentation use separate and dissimilar networks when perform the panoptic segmentation. But in this paper, for unify these methods at the architectural level, FAIR design a single network by endowing Mask R-CNN with a semantic segmentation branch using a shared FPN backbone.
DensePose
DensePose is a kind of dense human pose estimation, which maps pixel information of all people in the RGB image to the 3D surface of the human body. Provided model is DensePose-RCNN that learns through COCO dataset consisted of 50,000 surface annotated images.
Reference
Mask R-CNN, Panoptic Segmentation, DensePose, facebookresearch/detectron2,